tracking my music tastes with the spotify API
Introduction
Every year in December Spotify releases a personalized “year-in-review” that gives each Spotify user a look at what and how much music they listened to over the year. This also comes with a 100 song playlist of your most listened to tracks for the year. Now I recently learned that Spotify keeps features about each track, like ‘acousticness’ and ‘danceability’ as well as boring music theory stuff (I jest) like cadence key, and time signature. Presumably they use it for new music recommendations and to prevent large mood swings when shuffling (I’m telling you right now it is NOT random). I figured I could learn something about how my music tastes have changed over time from these features and my most played tracks - so I explored how to access my data and the track data with the Spotify API.
Get that data
The API is well documented and can be accessed by anyone for free, but you will need authorization from each user you want to collect data on. This is not a problem for your own data, however! I used the Python library “Spotipy”, which provides a host of wrapper functions to make authorization and calls to the API straightforward. First I defined a couple of function that will help me down the road:
import spotipy
import pprint
from spotipy.oauth2 import SpotifyOAuth
## Define functions that will help us down the road
def get_yearly_top_songs_plid(top_songs_pl, playlist):
"""Checks if a playlist name fits the yearly 'Top Songs' pattern """
check_string = "Your Top Songs"
if check_string in playlist['name']:
top_songs_pl.append(playlist)
print("Found yearly playlist with name: {}".format(playlist['name']))
def get_track_ids(playlist_response_object):
"""Gets all the track ids from a playlist"""
track_ids = []
try:
for track in playlist_response_object["tracks"]:
track_ids.append(track["track"]["id"])
return track_ids
except:
("Something went wrong")
def chunks(lst, n):
"""Yield successive n-sized chunks from list."""
for i in range(0, len(lst), n):
yield lst[i:i + n]
def get_year_from_playlist_name(playlist_object):
"""Gets the year from the playlist name"""
year = re.findall("20\d\d", playlist_object['name'])
if year[0] is not None:
return year[0]
def get_track_features(chunked_track_ids):
"""Makes API calls with the track IDs to get info and features"""
track_info = []
track_features = []
for chunk in chunked_track_ids:
track_info_chunk = sp.tracks(chunk)
track_features_chunk = sp.audio_features(chunk)
track_info.extend(track_info_chunk['tracks'])
track_features.extend(track_features_chunk)
return track_info, track_features
The chunks() function is necessary because you can only fetch information from a certain number of songs at a time, and somehow my 2016 top 100 songs has 101 songs?? With those helpers defined, we can connect the app with OAuth and make our API calls. You have to set a scope when you connect, and for this project all I needed was to be able to read from my playlists.
# Set up our scope and connection.
scope = 'playlist-read-private'
auth_manager = SpotifyOAuth(client_id = "client_id",
client_secret = "client_secret",
redirect_uri = 'App URL',
scope = scope)
sp = spotipy.Spotify(auth_manager=auth_manager)
With that set up I can start making calls to the API to get information about my playlists, and using my helper function above, to get the track names from each playlist:
playlists = sp.current_user_playlists(limit=50)
top_songs_playlists = []
#Loop through the playlists and save the ID of the top songs playlists
while playlists:
for i, playlist in enumerate(playlists['items']):
get_yearly_top_songs_plid(top_songs_playlists, playlist)
if playlists['next']:
playlists = sp.next(playlists)
else:
playlists = None
#Get the total number of years for which I have a top songs playlist
num_years = len(top_songs_playlists)
#Loop through the top songs playlist and get the tracks - added to a dictionary
for year in range(num_years):
print("Finding tracks from {}".format(top_songs_playlists[year]['name']))
pl_id = top_songs_playlists[year]["uri"]
offset = 0
year_tracks = []
while True:
response = sp.playlist_items(pl_id,
offset=offset,
fields='items.track.id,total',
additional_types=['track'])
if len(response['items']) == 0:
break
num_tracks = response['total']
year_tracks.extend(response['items'])
offset = offset + len(response['items'])
print("Found {} tracks".format(num_tracks))
top_songs_playlists[year]["tracks"] = year_tracks
With my dictionary of years:songs I can now loop through all the tracks and get the song info and the features.
track_info = []
track_features = []
for playlist in top_songs_playlists:
print("Getting features for {}".format(playlist['name']))
year = get_year_from_playlist_name(playlist)
print(year)
#helper function to get track ids from a playlist object
track_ids = get_track_ids(playlist)
print(len(track_ids))
#chunkify to not overload the API
track_ids_chunks = list(chunks(track_ids, 50))
#This function calls the API to get the track features and information
year_tracks_info, year_tracks_features = get_track_features(track_ids_chunks)
#Add the year it was in my top songs to each track instance
for item in year_tracks_features:
item.update( {"year": year})
for item in year_tracks_info:
item.update( {"year": year})
#Add the track info and features from the specific year to the whole dataset
track_info.extend(year_tracks_info)
track_features.extend(year_tracks_features)
Now all I did was do a left join of track_info and track_features and save it for use in R.
Analysis
The first thing I am interested in is how the average features over the playlist change through the years. To do this I used the group_by() function to group the features by year and then summarise() in conjunction with mean() to get a dataframe of the mean audio feature per year. The plot of the features over time is below:
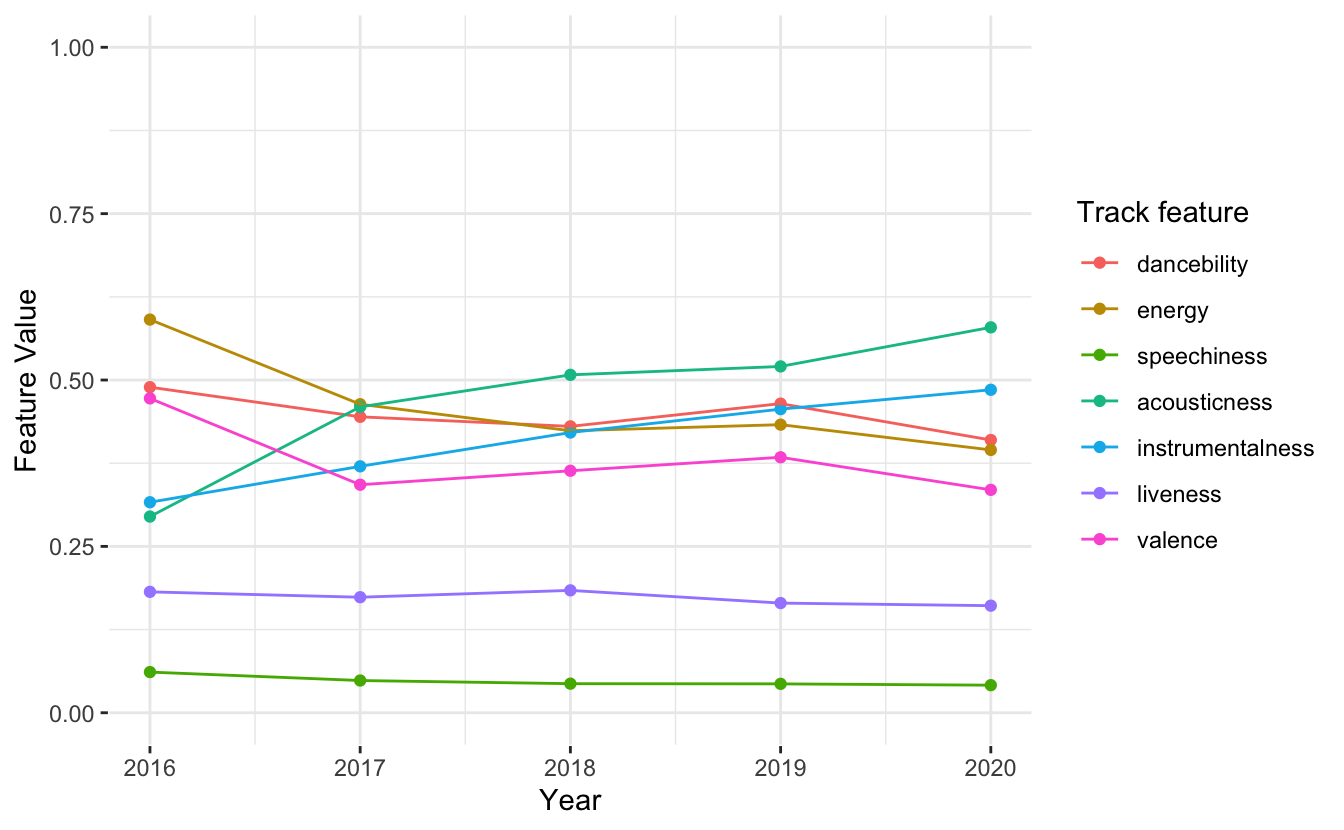
As it appears, I am becoming more boring. The mean energy of my top tracks, as well as the mean dancebility, is decreasing. On the other hand, the mean acousticness and instrumentalness is increasing. Have I started listening to more classical music? I manually coded whether a track was classical or not - but you may be able to pull it from the artist. In Spotify, genre is stored in the artists pbject, not in the song or album information. Keeping in mind that 2016 has 101 songs somehow, here is the proportion of classical music over time:
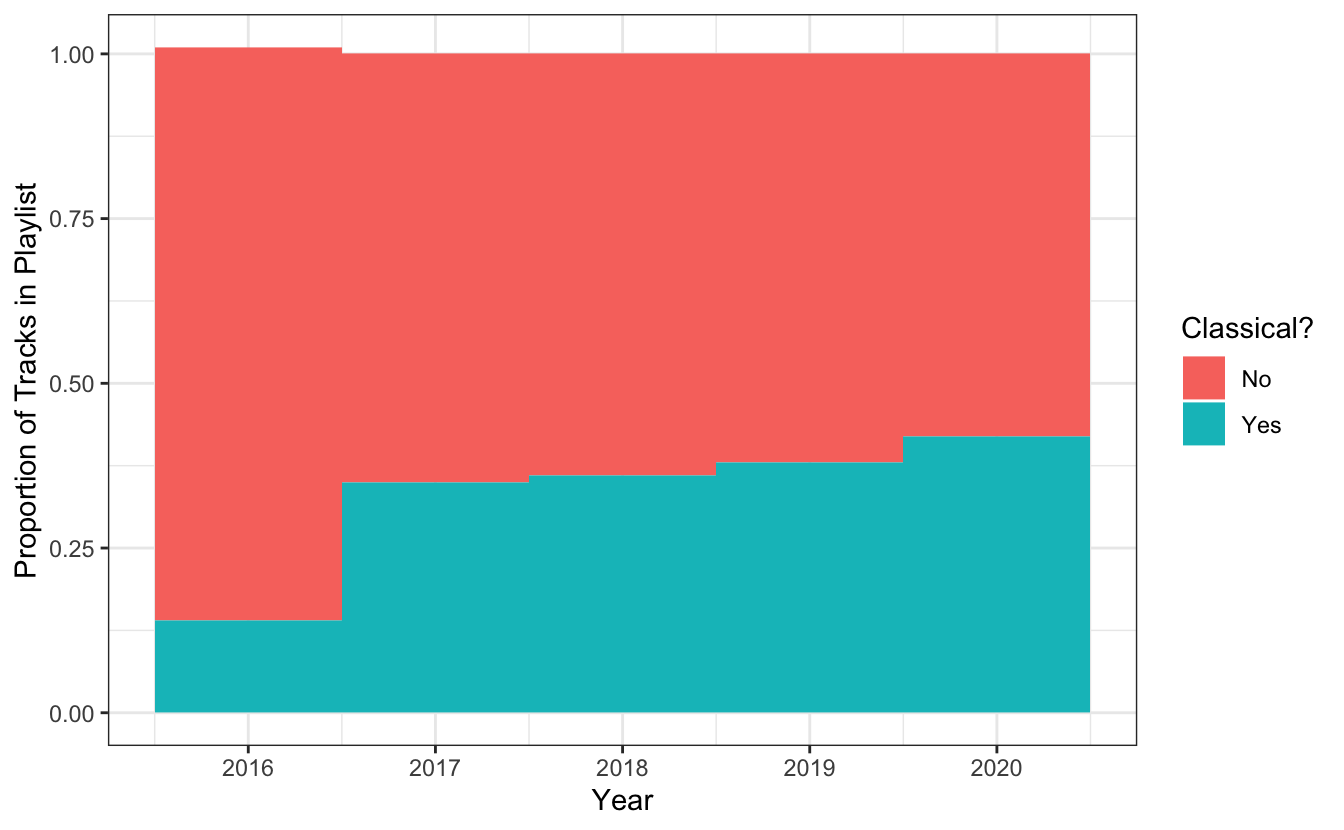
The answer is yes - I have been listening to more classical music since 2016. But that doesn’t tell the whole story. Classical music tracks are, on average, longer than non-classical tracks. So while the genre classical represents about a third of my top tracks each year, the proportion of time spent listening to classical music is larger than that.
Lastly I’ll take a peek at the distribution of the popularity metric among my top songs from 2016 to 2020. The popularity is a metric from 0 (20th Century French Organ Music) to 100 (Ariana Grande), so we can see how obscure my music tastes are.
| Track Name | Artist | Album Name | Popularity | Year |
|---|---|---|---|---|
| Dreams - 2004 Remaster | [‘Fleetwood Mac’] | Rumours (Super Deluxe) | 85 | 2020 |
| Dreams - 2004 Remaster | [‘Fleetwood Mac’] | Rumours (Super Deluxe) | 85 | 2019 |
| Resonance | [‘Home’] | Odyssey | 69 | 2018 |
| Passionfruit | [‘Drake’] | More Life | 78 | 2017 |
| Africa | [‘TOTO’] | Toto IV | 81 | 2016 |
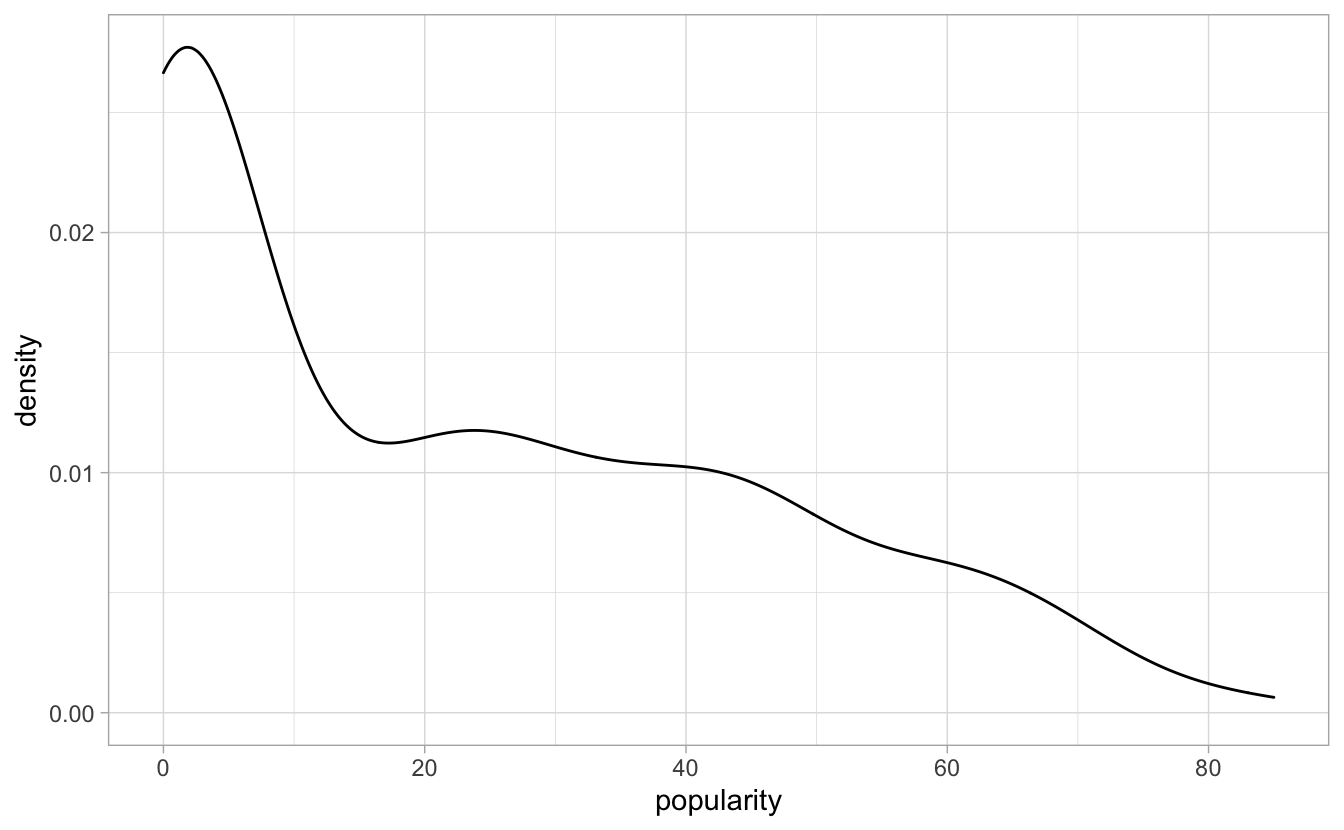
My most popular songs are from Fleetwood Mac and Drake - but on the whole my music tastes are not very popular, which I blame on Jean Langlais.
Conclusion
There are plenty of more questions I could ask of my data, such as:
-
Is my top 20 songs playlist, which I curated to be representative of my tastes, actually representative of my tastes? Or, what tracks, described by their feature vector, are contained in the hyperplane defined by the tracks in the top 20 songs playlist. I think this could be visualized with PCA. On the other hand, these songs don’t likely represent extrema, and may capture a certain proportion of the center, should the features be normally distributed.
-
How much of my top songs stay the same from year to year?
-
How have my music tastes by decade changed over time? If the proportion of classical music is any indication, the decades from 1900-1940 should be on the up.
And so on. Feel free to reach out if you have any questions about how I accessed the data or for any other reason. Thanks!